Optimize YOLOv5 Execution on VEK280#
The X+ML system combines the strengths of NPUs and FPGAs to balance high performance and precision in AI tasks.
Note
NPUs: Specialized for AI workloads, these processors use lower-precision formats (for example, 8-bit integers) for faster computation and energy efficiency. However, lower precision can sometimes impact accuracy, especially in tasks requiring high numerical precision (for example, scientific computing or financial modeling).
Note
PL IP (on FPGA): A specialized hardware component implemented on an FPGA, designed to handle high-precision computations required by specific parts of a model, such as the YOLOv5 Tail Graph.
The following sections demonstrate the tail graph acceleration of the YOLOv5 model with the X+ML reference design.
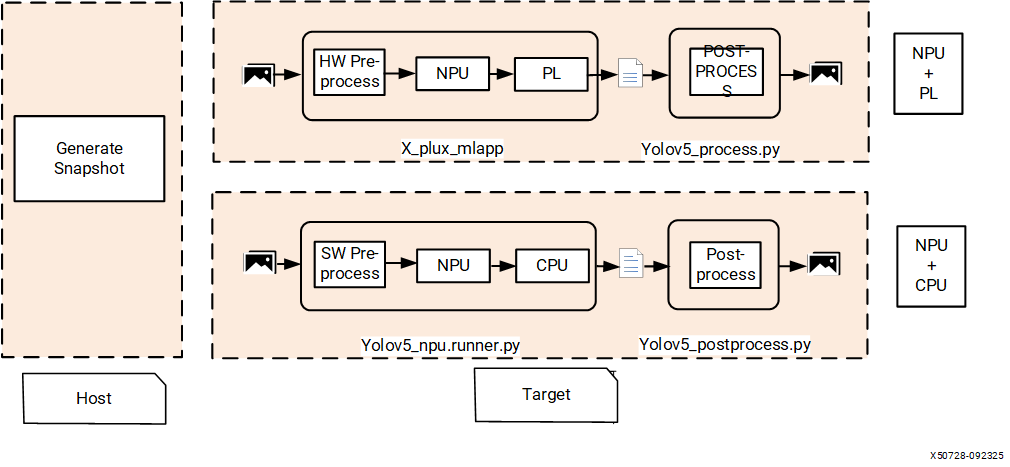
Executing YOLOv5 on NPU and PL#
The YOLOv5 model execution divides into two parts:
Part |
Description |
|---|---|
NPU Graph |
Most tasks execute efficiently on the NPU. |
Tail Graph |
High-precision operations that would traditionally run on the CPU execute on the FPGA using PL IP. |
The PL IP manages high-precision (16-bit) computations, ensuring both high speed and accuracy. This offloads intensive tasks from the CPU, enhancing AI performance and overall system efficiency. As a pre-compiled, hardcoded IP, it is included in the xclbin for seamless integration.
Execution Process#
Model Partitioning#
During compilation and snapshot creation, the NPU compiler splits the YOLOv5 model into two graphs:
Graph |
Description |
|---|---|
NPU Graph |
Operations supported by the NPU are saved as wrp_network_iriz.onnx and run on the NPU for efficiency. |
Tail Graph |
Operations requiring higher precision or unsupported by the NPU are saved as wrp_network_CPU.onnx. This graph executes on the FPGA via PL IP. |
Graph Execution#
NPU Execution: The NPU graph processes on the NPU, delivering speed and energy efficiency.
Tail Execution: The Tail Graph, referred to as
wrp_network_CPU.onnx, contains high-precision tasks executed on FPGAs (through VAI-PL IP) instead of the CPU. The PL takes the native NPU output as input and produces results identical to the ONNX graph.
Post-Processing#
Outputs from the PL undergo post-processing to generate the final YOLOv5 detections.
Steps to Execute YOLOv5 with NPU and PL on VEK280#
Create a Snapshot Use the Vitis AI Docker to create a snapshot of the YOLOv5 model for the VEK280 hardware. Execute the following commands to set up the environment and ensure the snapshot is created for performance IP:
$ cd $VITIS_AI_REPO $ source npu_ip/settings.sh VE2802_NPU_IP_O0_A304_M3 --nofallback
Generate the snapshot using the command:
$ ./docker/run.bash --acceptLicense -- /bin/bash -c "source npu_ip/settings.sh && cd /home/demo/yolov5 && VAISW_SNAPSHOT_DUMPIOS=5 VAISW_SNAPSHOT_DIRECTORY=$PWD/SNAP.$NPU_IP/yolov5.b1 VAISW_QUANTIZATION_NBIMAGES=1 ./run data/images/bus.jpg --out_file /dev/null --ext pt"
This creates: -
wrp_network_iriz.onnx(NPU graph) -wrp_network_CPU.onnx(Tail graph for FPGA execution)Deploy the Graphs Copy the generated graphs to the VEK280 board, pre-flashed with the reference design image containing the
yolov5_tailPL kernel.Execute Using x_plus_ml_app Use
x_plus_ml_appto run the entire workflow. This tool reads the PL kernel information from a JSON file and coordinates the NPU and PL execution.
x_plus_ml_app Workflow Details
Input Preprocessing:
x_plus_ml_appaccepts a JPEG image and preprocesses it using image-processing IP.Copy the
bus.jpgfile (which is available at/home/demo/yolov5/data/images/bus.jpginside the docker) to VEK280 board.$ source /etc/vai.sh $ x_plus_ml_app -i bus.jpg -c /etc/vai/json-config/yolov5_pl.json -s yolov5.b1 -r 1Use “-r 0” to stop dumping the NPU results to capture performance numbers.
$ x_plus_ml_app -i bus.jpg -c /etc/vai/json-config/yolov5_pl.json -s yolov5.b1 -r 0NPU Execution:
The preprocessed image processes on the NPU, generating native outputs for the PL.
PL Execution:
The PL kernel (
yolov5_tail) processes the NPU’s output, ensuring high-precision computation and generating results identical to the ONNX graph.
Execute Using yolov5_npu_runner Python App Use
yolov5_npu_runner.pyto run the entire workflow. This tool usesVART.py, which reads the model input/output information from the snapshot and coordinates the NPU and ONNX execution.yolov5_npu_runner Workflow Details
Input Preprocessing:
The Python app accepts a JPEG image and preprocesses it using Python libraries.
# Install onnxruntime if not already installed $ pip3 install onnx $ pip3 install onnxruntime # Install PIL for image processing $ pip3 install Pillow $ source /etc/vai.sh $ VAISW_USE_RAW_OUTPUTS=1 python3 /usr/bin/yolov5_npu_runner.py --snapshot yolov5.b1 --image bus.jpg --dump_output # Remove --dump_output to capture performance numbers $ VAISW_USE_RAW_OUTPUTS=1 python3 /usr/bin/yolov5_npu_runner.py --snapshot yolov5.b1 --image bus.jpg
NPU Execution:
The preprocessed image processes on the NPU, generating native outputs for the ONNX graph.
ONNX Graph Execution on CPU:
The
onnxruntimeprocesses the NPU’s output on the CPU, ensuring high-precision computation and generating results.Output Validation:
Outputs from the PL kernel via
x_plus_mland ONNX through the Python app dump into files (/tmp/app_hls_output0_0_488_1.binand/tmp/yolov5_output0_0.rawrespectively) for validation. The reference image comes withyolov5_postprocess.pyapp, which takes dumped outputs from the previous applications, performs post-processing, and outputs the results on the screen.Install the following packages on the board before running the app:
$ pip3 install torch $ pip3 install torchvision $ pip3 install onnx $ pip3 install onnxruntime
Run the following script (part of the reference design) to validate and post-process the outputs:
$ python3 /usr/bin/yolov5_postprocess.py --pred_data /tmp/app_hls_output0_0_488_1.bin --image bus.jpg $ python3 /usr/bin/yolov5_postprocess.py --pred_data /tmp/yolov5_output0_0.raw --image bus.jpg
Final Output:
The post-processed results display on screen and also draw on the input image and save as the final output (
bus_detection_results.jpg).The console output and annotated output is:
Annotated image saved to: bus_detection_results.jpg Class: person, Score: 0.90, Box: [227.49609375, 396.5625, 339.50390625, 865.6875] Class: person, Score: 0.87, Box: [48.09375, 379.6875, 241.734375, 929.8125] Class: person, Score: 0.84, Box: [674.89453125, 383.0625, 803.35546875, 879.1875] Class: bus, Score: 0.56, Box: [0.0, 200.8125, 799.875, 784.6875]

Performance Comparison#
The following table presents a performance comparison between the NPU+PL and NPU+CPU configurations for YOLOv5 inference on the VEK280 hardware:
Note
The following numbers do not include preprocessing and post-processing.
Metric |
x_plus_ml_app (NPU + PL) |
yolov5_npu_runner.py (NPU + CPU) |
Gain |
|---|---|---|---|
Average Total NPU Graph Execution Time (10 Frames) |
16.1471 ms |
15.829 ms |
|
Average Total Tail Graph Execution Time (10 Frames) |
3.5469 ms |
36.9 ms |
~10x |
Average Total Inference Time (Sequential Flow) (10 Frames) |
(NPU + PL) 19.6945 ms |
(NPU + CPU) 53.31 ms |
>2x |
This demonstrates the advantage of using the hybrid NPU+PL approach, which combines speed and accuracy while reducing CPU workload.
To get the performance numbers, execute the following commands:
# Using x_plus_ml_app (NPU + PL)
$ x_plus_ml_app -i bus.jpg -c /etc/vai/json-config/yolov5_pl.json -s yolov5.b1 -m 10
This command generates the following output:
root@xilinx-vek280-20241:~# x_plus_ml_app -i bus.jpg -c /etc/vai/json-config/yolov5_pl.json -s yolov5.b1 -m 10
XAIEFAL: INFO: Resource group Avail is created.
XAIEFAL: INFO: Resource group Static is created.
XAIEFAL: INFO: Resource group Generic is created.
XAIEFAL: INFO: Resource group Avail is created.
XAIEFAL: INFO: Resource group Static is created.
XAIEFAL: INFO: Resource group Generic is created.
Found snapshot for IP VE2802_NPU_IP_O0_A304_M3 matching running device VE2802_NPU_IP_O0_A304_M3
XAIEFAL: INFO: Resource group Avail is created.==========]
XAIEFAL: INFO: Resource group Static is created.
XAIEFAL: INFO: Resource group Generic is created.
Frame 1
NPU graph: 17.182 ms
PL graph: 3.552 ms
Total Inference (NPU + PL) took 20.735 ms
Frame 2
NPU graph: 16.083 ms
PL graph: 3.524 ms
Total Inference (NPU + PL) took 19.608 ms
Frame 3
NPU graph: 14.903 ms
PL graph: 3.524 ms
Total Inference (NPU + PL) took 18.428 ms
Frame 4
NPU graph: 15.596 ms
PL graph: 3.522 ms
Total Inference (NPU + PL) took 19.119 ms
Frame 5
NPU graph: 14.892 ms
PL graph: 3.537 ms
Total Inference (NPU + PL) took 18.43 ms
Frame 6
NPU graph: 15.609 ms
PL graph: 3.523 ms
Total Inference (NPU + PL) took 19.132 ms
Frame 7
NPU graph: 14.894 ms
PL graph: 3.525 ms
Total Inference (NPU + PL) took 18.42 ms
Frame 8
NPU graph: 15.591 ms
PL graph: 3.523 ms
Total Inference (NPU + PL) took 19.115 ms
Frame 9
NPU graph: 14.902 ms
PL graph: 3.525 ms
Total Inference (NPU + PL) took 18.428 ms
Frame 10
NPU graph: 15.591 ms
PL graph: 3.521 ms
Total Inference (NPU + PL) took 19.113 ms
Number of frames processed: 10
Average Total Inference Time for 10 Frames: 19.0528 ms
Average NPU Time for 10 Frames: 15.5243 ms
Average PL Time for 10 Frames: 3.5276 ms
root@xilinx-vek280-20241:~#
To get the performance numbers for “NPU+CPU”, execute the following command: .. code-block:: shell
# Using yolov5_npu_runner.py (NPU + CPU) $ VAISW_USE_RAW_OUTPUTS=1 python3 /usr/bin/yolov5_npu_runner.py –snapshot yolov5.b1 –image bus.jpg –num_inferences 10
This command produces the following output:
root@xilinx-vek280-20241:~# VAISW_USE_RAW_OUTPUTS=1 python3 /usr/bin/yolov5_npu_runner.py --snapshot yolov5.b1 --image bus.jpg --num_inferences 10
Creating runner for subGraph wrp_network_ZEBRA
Constructor called with path yolov5.b1 and verbose 1
Parsing snapshot:
XAIEFAL: INFO: Resource group Avail is created.
XAIEFAL: INFO: Resource group Static is created.
XAIEFAL: INFO: Resource group Generic is created.
Found snapshot for IP VE2802_NPU_IP_O0_A304_M3 matching running device VE2802_NPU_IP_O0_A304_M3
Snapshot fully parsed, FPGA networks contains 1 input layer and 3 output layer:
input 0 input.1 with shape ( 1 3 640 640 ) and ddr offsets:
bufferId 0:
batch 0 @ 0xaaa06a0918c4 with size 1638400
output 0 Conv_206 with shape ( 1 255 80 80 ) and ddr offsets:
bufferId 0:
batch 0 @ 0xaaa06a0918c4 with size 1638400
output 1 Conv_245 with shape ( 1 255 40 40 ) and ddr offsets:
bufferId 0:
batch 0 @ 0xaaa06a0918c4 with size 409600
output 2 Conv_284 with shape ( 1 255 20 20 ) and ddr offsets:
bufferId 0:
batch 0 @ 0xaaa06a0918c4 with size 102400
Creating runner for subGraph wrp_network_CPU
Loading model of type CPU from yolov5.b1/wrp_network_CPU.onnx
All raw_outputs compliant subgraphs already exists: {1: 'yolov5.b1/wrp_network_CPU_raw_outputs.onnx'} skipping modification.
Frame 1
Total Inference (NPU + ONNX Graph) took 64.15 ms
Frame 2
Total Inference (NPU + ONNX Graph) took 67.54 ms
Frame 3
Total Inference (NPU + ONNX Graph) took 47.37 ms
Frame 4
Total Inference (NPU + ONNX Graph) took 47.73 ms
Frame 5
Total Inference (NPU + ONNX Graph) took 47.41 ms
Frame 6
Total Inference (NPU + ONNX Graph) took 47.56 ms
Frame 7
Total Inference (NPU + ONNX Graph) took 47.55 ms
Frame 8
Total Inference (NPU + ONNX Graph) took 47.67 ms
Frame 9
Total Inference (NPU + ONNX Graph) took 47.43 ms
Frame 10
Total Inference (NPU + ONNX Graph) took 47.92 ms
Average Total Inference Time for 10 Frames: 51.23 ms
root@xilinx-vek280-20241:~#
x_plus_ml_app JSON File#
Currently, the PL information in JSON is handwritten. Ensure the proper TensorSize and that the name of the NPU output tensor matches the name mentioned in JSON.
{
"xclbin-location": "/run/media/mmcblk0p1/x_plus_ml.xclbin",
"use-native-output-format": true,
"preprocess-config": {
"mean-r": 0,
"mean-g": 0,
"mean-b": 0,
"scale-r": 0.0039215,
"scale-g": 0.0039215,
"scale-b": 0.0039215,
"colour-format": "RGB",
"maintain-aspect-ratio": false,
"in-mem-bank": 2,
"out-mem-bank": 2
},
"plkernel-config": {
"modelName": "yolov5s-subgraph-0",
"_comment_modelName": "Each subgraph has its own JSON file, with a number appended to it",
"kernelName": "yolov5_tail",
"_comment_Arguments": "Arguments should be in the same order in which PL support.",
"Arguments": [
{
"layerName": "Conv_284",
"shape": [1, 255, 20, 20],
"shapeFormat": "NATIVE",
"direction": "INPUT",
"stride": [1, 1, 1, 1],
"dataType": "INT8",
"TensorSize": 102400,
"coef": 1
},
{
"layerName": "Conv_206",
"_comment_layerName": "The name should match the input argument of the HLS and the name of the output tensor from the NPU.",
"shape": [1, 255, 80, 80],
"shapeFormat": "NATIVE",
"_comment_shapeFormat": "This indicates whether any conversion is needed for the NPU outputs.",
"direction": "INPUT",
"_comment_direction": "Indicates whether it is input args or output args for PL",
"stride": [1, 1, 1, 1],
"_comment_stride": "It’s tricky to provide the NPU’s native format in JSON, so the NPU should output in a normal format, and the HLS should accept that as it is.",
"dataType": "INT8",
"_comment_dataType": "The NPU outputs in INT8 format, and the HLS should use the same format to avoid the need for un-quantization.",
"TensorSize": 1638400,
"coef": 1
},
{
"layerName": "Conv_245",
"shape": [1, 255, 40, 40],
"shapeFormat": "NATIVE",
"direction": "INPUT",
"stride": [1, 1, 1, 1],
"dataType": "INT8",
"TensorSize": 409600,
"coef": 1
},
{
"layerName": "488",
"shape": [1, 25200, 85],
"shapeFormat": "NCHW",
"direction": "OUTPUT",
"stride": [1, 1, 1, 1],
"dataType": "FLOAT32",
"_comment_dataType": "The tricky part is that ONNX requires tensors to be in float format. Therefore, HLS should provide data in float format to avoid the need for un-quantization on the CPU. If the data type is INT8, the coefficient value should be provided.",
"TensorSize": 8568000,
"coef": 1
}
]
}
}
This approach ensures the system achieves an optimal balance of speed and accuracy:
Speed: NPUs efficiently execute the bulk of computations.
Accuracy: PL handles tasks that demand high precision without burdening the CPU.
By leveraging this hybrid execution model, the X+ML system optimizes performance for AI workloads while meeting the precision requirements of critical tasks.