VART ML Architecture Overview#
VART-ML is a high-performance C++ runtime interface for ML inference on AMD hardware. It supports fully offloaded models—the compiled graph runs entirely on the NPU—and models compiled with the CPU partition feature, which enables heterogeneous NPU/CPU execution using compiler-supported CPU operators. For models that require runtime CPU fallback or broad ONNX operator coverage not handled by CPU partition compilation, use ONNX Runtime with the Vitis AI Execution Provider instead.
VART-ML is designed to:
Execute fully offloaded models on the NPU, and CPU-partitioned models across NPU and CPU subgraphs as defined at compile time.
Expose explicit control of tensor metadata and buffer ownership.
Support both CPU-view and hardware-view tensor flows.
Enable zero-copy execution when hardware-visible memory is used.
Note
For a runtime-selection comparison between VART-ML and ONNX Runtime + Vitis AI EP, see Introduction: VART X and VART ML.
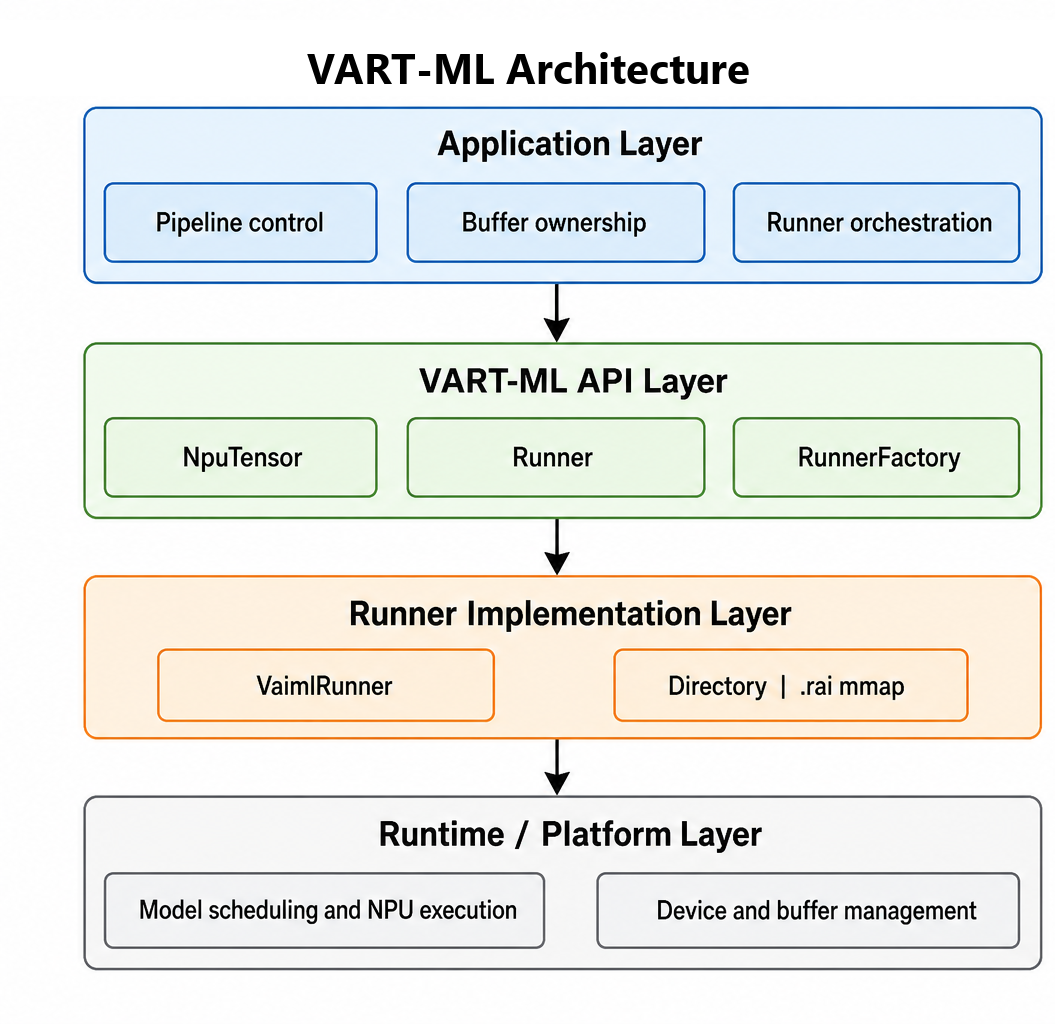
Layered Architecture#
Layer |
Role |
|---|---|
Application layer |
Owns pipeline control, creates runners, allocates/wraps buffers, and invokes sync/async execution. |
VART-ML API layer |
Public abstractions: |
Runner implementation layer |
Vitis AI compiler and runtime stack backend implementation handling model loading, metadata, execution, and tensor allocation helpers. |
Runtime/platform layer |
Model scheduling, NPU execution, device management, and hardware-backed buffer allocation. |
Core Abstractions#
VART-ML centers around three abstractions:
NpuTensor: Represents tensor metadata and wraps user-allocated or runner-allocated buffers. Supports explicit buffer synchronization (
sync_buffer) and DMA-BUF file descriptor export (export_buffer) for inter-process or inter-device sharing.Runner: Loads models, exposes metadata/quantization data, executes inference, and provides tensor allocation helpers including sub-tensor views (
allocate_sub_tensor) for efficient batch memory management.RunnerFactory: Creates runner instances for supported backends.
Execution Architecture#
Typical integration workflow:
Create a
RunnerviaRunnerFactoryfor a compiled model.Query tensor metadata in CPU or HW view.
Allocate or wrap buffers and construct
NpuTensorobjects.Execute inference using synchronous
executeor asynchronousexecute_asyncAPIs.Consume outputs in CPU or HW view depending on postprocessing path.
Synchronous flow:
executeblocks until completion.
Asynchronous flows:
execute_async+waitfor job-handle driven completion.execute_async+ callback for completion notification.
Tensor and Memory Architecture#
VART-ML supports two tensor views:
CPU TensorType: Tensor metadata as defined by the ONNX model (standard shapes, data types, and layouts). Use CPU tensors for simplicity – the Runner converts between CPU and HW formats internally, at the cost of a data copy.
HW TensorType: AMD NPU-native tensor metadata. Shape, data type, and memory layout might differ from the CPU view. For example, a model with CPU format
NCHW, FP32, [1,3,224,224]might have HW formatHCWNC4, BF16, [224,1,224,1,4]. Use HW tensors for zero-copy performance – data goes to the NPU without conversion.
Input and output tensor types can be configured independently (for example, HW input with CPU output).
Each NpuTensor has a memory type that determines where the buffer lives and whether zero-copy is possible:
XRT_BO– XRT Buffer Object, device-accessible CMA memory. Use when the Runner allocates memory (allocate_npu_tensor) or when the application already manages XRT BOs.DMA_FD– DMA file descriptor. Recommended for application-allocated zero-copy buffers; portable across Linux subsystems (V4L2, dma_heap, ISP, video decoder).USER_POINTER_CMA– User-provided pointer to physically contiguous (CMA) memory. Use when you have a CMA buffer from another allocator.USER_POINTER_NON_CMA– Standard host memory (new,malloc). Use for standard workflows without hardware awareness. Not physically contiguous; the Runner copies data internally.
Zero-copy behavior:
Supported when
TensorType = HWand memory type isXRT_BO,DMA_FD, orUSER_POINTER_CMA.Invalid:
TensorType = HWwithUSER_POINTER_NON_CMA– this combination throwsstd::runtime_erroratNpuTensorconstruction because non-CMA memory is not accessible by the NPU.Not zero-copy:
TensorType = CPUwith any memory type – the Runner performs format conversion internally, which involves a data copy.
The same execution APIs support both zero-copy and non-zero-copy paths; tensor view and memory choice determine behavior.
NpuTensor Ownership#
User-constructed tensors:
NpuTensordoes not take ownership of the buffer. The caller must keep it valid for the tensor’s lifetime.Runner-allocated tensors (via
allocate_npu_tensor): The buffer is owned by theNpuTensorand freed automatically when it goes out of scope (RAII).Sub-tensors (via
allocate_sub_tensor): Share the parent tensor’s buffer via reference counting. The underlying memory is released only after both the parent and all derived sub-tensors are destroyed. Only one level of nesting is supported.
See also
For implementation details and code examples on enabling zero-copy, see the advanced features section in VART Application Development.
Error Handling#
VART-ML uses a split error handling strategy:
Construction and queries (
create_runner,allocate_npu_tensor,get_tensor_info_by_name): Throwstd::runtime_errororstd::invalid_argument.Execution (
execute,execute_async,wait): ReturnStatusCode, markednoexcept.Accessors (
get_buffer,get_virtual_address): Return sentinel values (nullptr,0) on failure.
Thread Safety#
A single
Runnerinstance can be shared across threads viastd::shared_ptr.execute()andexecute_async()can be called concurrently from multiple threads.wait()calls are thread-safe.NpuTensorcopies sharing the same buffer can be used from different threads.Async callbacks are invoked from internal worker threads. Ensure thread safety when accessing shared resources in callbacks.
RunnerType::VAIML (Versal AI Edge Series Gen 2)#
The following sections are specific to RunnerType::VAIML.
Model loading modes#
RunnerType::VAIML accepts the compiled model in one of two artifact forms:
Directory-based: Load from a compiled model directory containing a
vaiml_par_0partition subdirectory with compiled model artifacts (graph definitions, metadata, and NPU binaries produced by the Vitis AI compiler)..rai memory-mapped: Load a
.raifile (single-file FlatBuffer archive of the compiled model) through memory mapping.
Configuration Options#
Runner creation accepts key-value options (unordered_map<std::string, std::any>) passed to RunnerFactory::create_runner(). All options are optional; defaults are listed in the following table.
Tensor Configuration:
Key |
Data Type |
Description |
Default |
|---|---|---|---|
|
String |
Sets input tensor type: |
|
|
String |
Sets output tensor type: |
|
|
Boolean |
Skip input buffer sync for HW tensor types. When true, sync input tensors before inference. For runner-allocated tensors ( |
|
|
Boolean |
Skip output buffer sync for HW tensor types. When true, sync output tensors before reading. For runner-allocated tensors ( |
|
NPU Resource Configuration:
Key |
Data Type |
Description |
Default |
|---|---|---|---|
|
Integer |
CMA memory bank index on which XRT BOs should be allocated by |
|
|
Boolean |
Sets access mode of the AI Engine columns; |
|
|
Unsigned~Integer |
Starting column index where the model is loaded |
Decided based on columns availability |
Async Execution Configuration:
Key |
Data Type |
Description |
Default |
|---|---|---|---|
|
Unsigned~Integer |
Number of threads in the thread pool for asynchronous execution |
|
|
Unsigned~Integer |
Maximum number of concurrent asynchronous runs allowed |
|
|
String |
Order in which callbacks are invoked for asynchronous runs. Accepted values: |
|
General:
Key |
Data Type |
Description |
Default |
|---|---|---|---|
|
String |
Logging verbosity. Accepted values: |
|
|
Boolean |
Enables or disables compiler debug messages |
|
|
String |
Path to the Vitis AI configuration file ( |
Null |
|
String |
Extraction path for .rai file loading. Only used with .rai model files |
Defaults to vaiml_ cache_ <model>_ <pid>_ <tid>_ <in the current directory |
|
Boolean |
Enables/disables AI Analyzer profiling logs |
|
Note
ai_analyzer_profiling adds memory and performance overhead. Use it only for short development and analysis runs—not for long-running sessions or production deployment.
Supported Layouts and Data Types#
The RunnerType::VAIML backend currently supports the following memory layouts. The MemoryLayout enum in the public header defines the full set across all backends.
NHWNHWCNCHWHCWNC4HCWNC8HCWNC16GENERIC
When the memory layout is GENERIC, the NpuTensorInfo::memory_layout_order vector specifies the dimension permutation order relative to the CPU tensor format.
The RunnerType::VAIML backend currently supports the following data types. The DataType enum in the public header defines the full set across all backends.
BOOLEANINT8UINT8INT16UINT16BF16FP16INT32UINT32FLOAT32INT64UINT64
Note
For detailed memory layout semantics and CPU/NPU transformations, see Tensor Format Conversions.
Notes and Recommendations#
To maximize performance:
Prefer zero-copy flow using HW tensors with device-visible memory.
Reuse
vart::NpuTensorinstances across runs to avoid repeated per-call construction overhead; see theNpuTensor Cachingsection in VART Application Development.
See also
For practical examples and reference applications using VART-ML APIs, see Reference Applications.
For step-by-step application development, see VART Application Development.