VART X Architecture Overview#
VART X provides modular C++ building blocks for end-to-end vision pipelines around model inference. It is focused on frame lifecycle, preprocessing, postprocessing, visualization, and device-aware data movement.
Note
For detailed initialization, usage, and code examples of VART-X modules, see VART Application Development.
Architecture Scope#
This document covers module boundaries, data and control flow, ownership expectations, and extension points for VART X.
Layered Architecture#
Layer |
Role |
|---|---|
Application layer |
Orchestrates pipeline stages, manages configuration, chooses inference backend (VART-ML or ONNX Runtime + EP), and controls pipeline policies. |
VART X API layer |
Public module interfaces such as Device, VideoFrame, PreProcess, PostProcess, MetaConvert, Overlay, Memory, InferResult, and PL Kernel. |
VART X implementation layer |
Module implementations and built-in presets/functions, hidden behind stable interfaces (pimpl-style design). |
Platform/runtime layer |
VVAS-CORE and XRT interactions for hardware-aware buffer management and acceleration. |
Design and Extension Model#
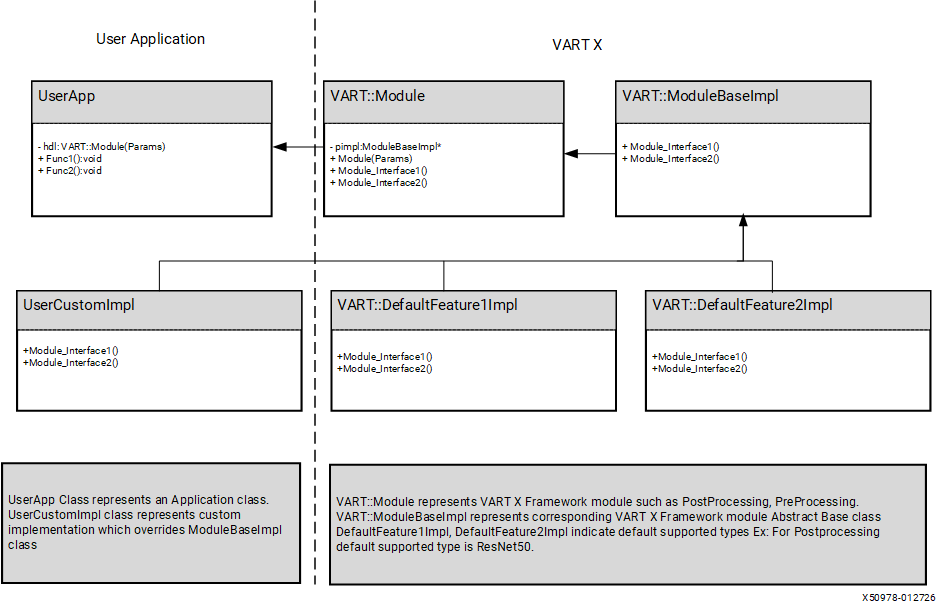
VART X follows a pimpl-style implementation pattern to keep interfaces stable while allowing implementation changes. Applications generally do not require relinking when internal module implementations change and public interfaces remain the same.
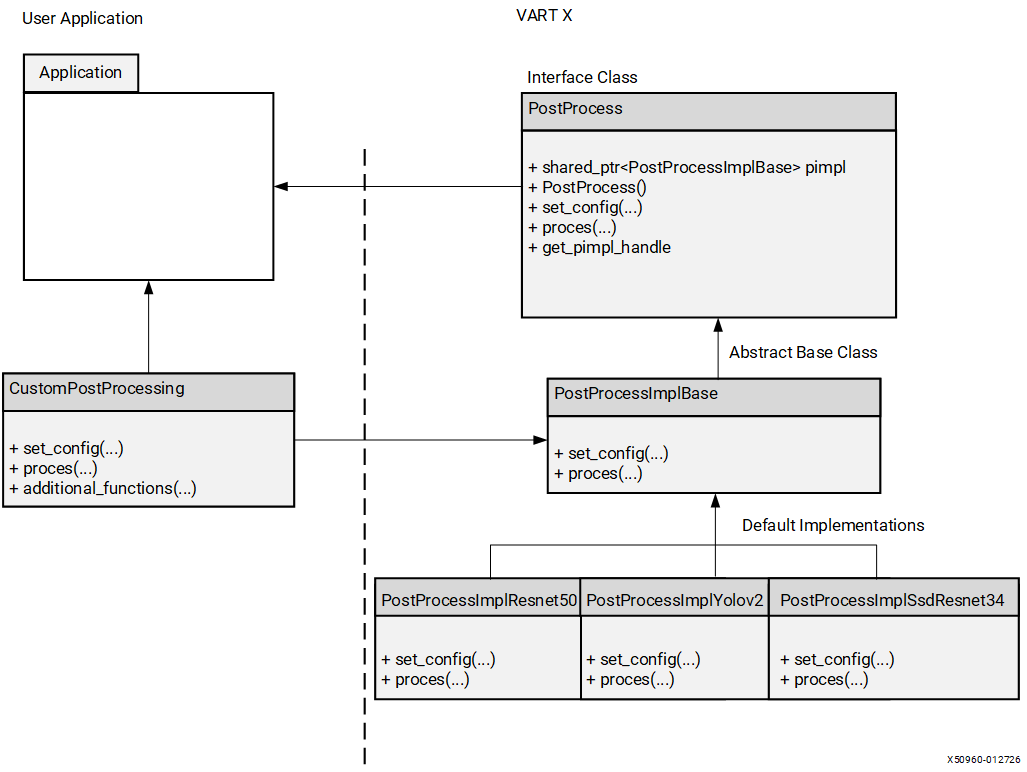
VART X includes model-oriented PostProcess presets (for example, YOLOv2, ResNet50, and SSD-ResNet34) plus a generic postprocess function set. For the complete list, see VART X APIs.
Note
If you use only built-in feature types, you do not need to provide custom ModuleBaseImpl classes.
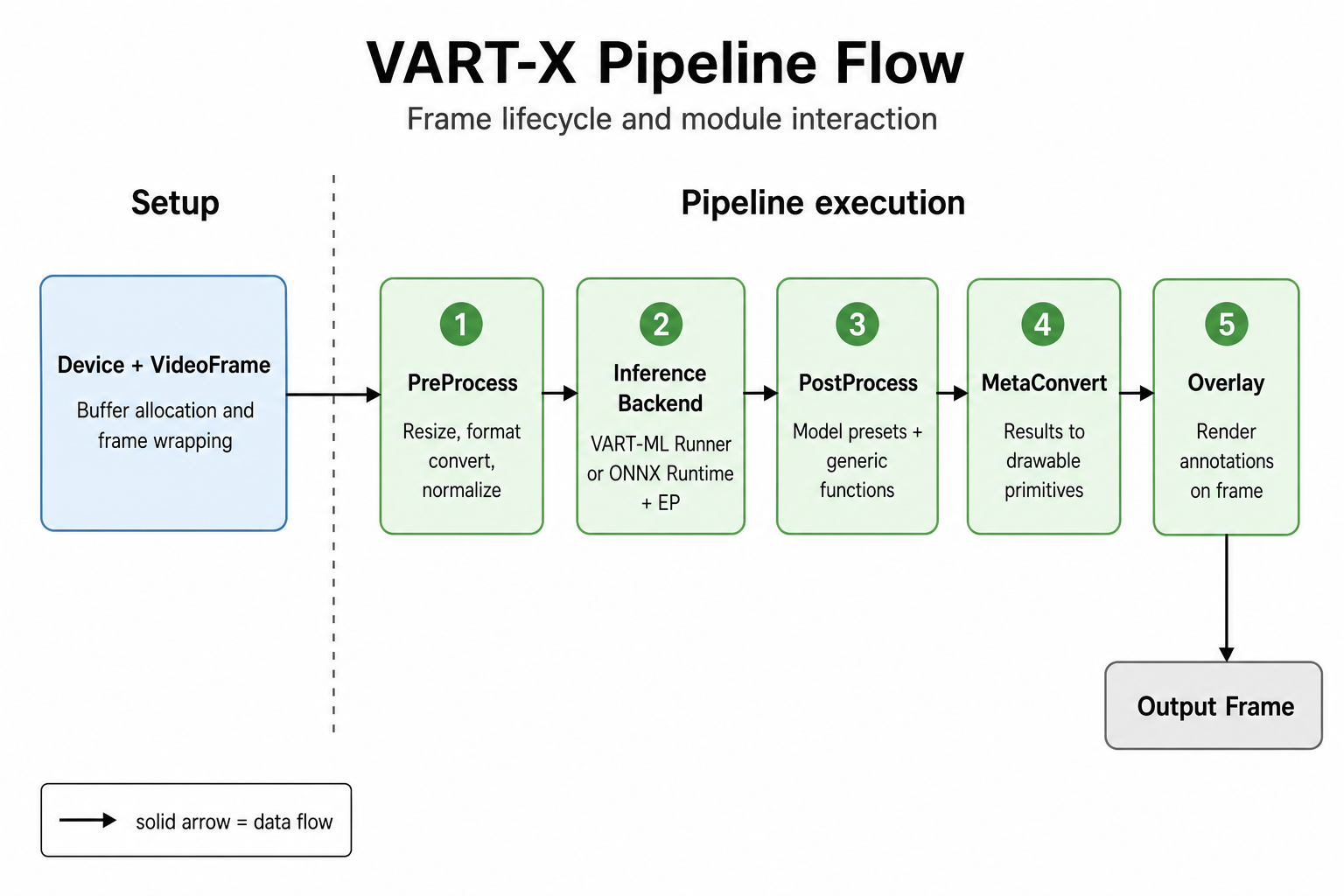
Pipeline Flow#
Note
The diagram shows logical pipeline order, not that every stage runs on the AI Engine/NPU. Inference (step 4 below) executes the compiled ML model on the AI Engine / NPU. PreProcess runs on programmable logic (PL) or the CPU, depending on configuration. PostProcess, MetaConvert, and Overlay run on the CPU; they are not that inference step.
A typical VART X-oriented flow is:
Create
Deviceand required module instances.Create or wrap
VideoFramebuffers for input and intermediate stages.Run
PreProcessto produce inference-ready frame/tensor data.Run inference using the selected backend (VART-ML Runner or ONNX Runtime + EP).
Convert raw outputs into
InferResultand runPostProcess.Run
MetaConvertto map results to drawable primitives.Run
Overlayto render annotations onto output frames.Optionally run
PL Kernelstages for additional tail processing.
Module Responsibilities#
Device: Manages hardware context and xclbin loading.
VideoFrame: Owns or wraps frame buffers; supports allocation, read/write, and deallocation for heap- and XRT-backed memory paths.
PreProcess: Performs normalization, resize, and format conversion with software and hardware-accelerated options.
PostProcess: Transforms raw inference outputs into meaningful results using built-in presets or generic function pipelines.
MetaConvert: Converts InferResult metadata into overlay-compatible structures with JSON-configurable rendering metadata.
Overlay: Draws annotations (for example boxes, text, lines, circles, polygons) on frames; default implementation is OpenCV-based.
InferResult: Represents output result structures, including classification, detection, and segmentation result types.
Memory: Provides device-aware memory allocation and management helpers.
PL Kernel: Enables tail-graph or custom PL-kernel execution with flexible argument passing (including std::any).
Ownership and Lifecycle#
Artifact |
Primary owner |
Lifecycle expectation |
|---|---|---|
|
Application |
Created early; shared by modules; valid for module lifetime. |
|
VART X object |
Allocated and released by VideoFrame lifecycle. |
|
Application |
Application remains responsible for underlying buffer lifetime. |
|
Application/pipeline stage |
Produced by inference/postprocess, then consumed by MetaConvert/Overlay. |
Integrating Custom Implementation#
Each VART X module exposes base classes for custom extension. Custom implementations can be integrated per module without changing application-level orchestration.
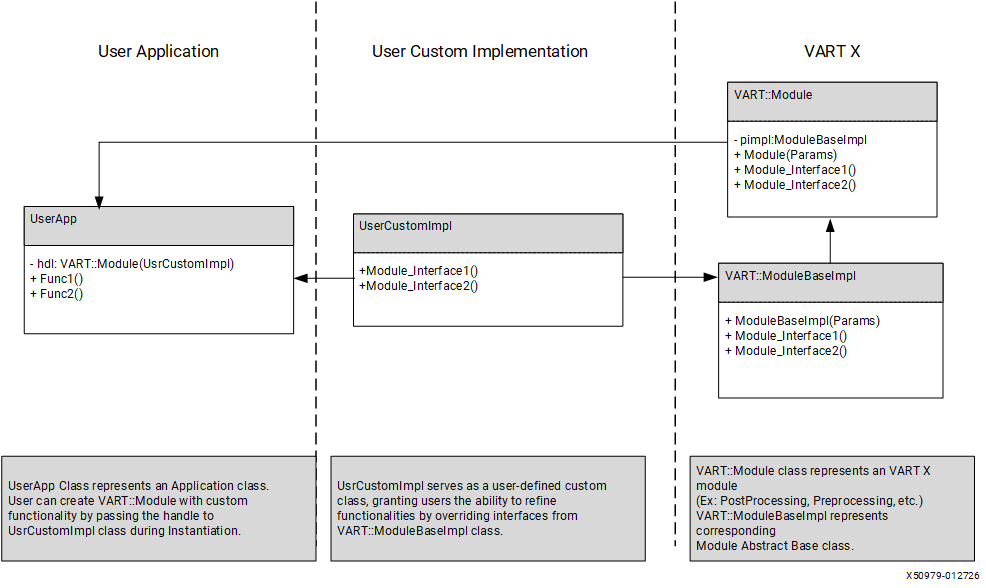
Every VART-X module uses the pimpl (pointer to implementation) pattern. Each interface class provides two constructors:
Built-in implementation: Accepts a type enum, JSON configuration, and device handle. Instantiates a VART-provided implementation internally.
User-provided implementation: Accepts a
shared_ptrto the module’s implementation base class. The user creates their own implementation and passes it directly – no factory registration or vart-x recompilation required.
The implementation base classes are:
PreProcessImplBaseforvart::PreProcessPostProcessImplBaseforvart::PostProcessMetaConvertImplBaseforvart::MetaConvertOverlayImplBaseforvart::Overlay
To integrate a custom implementation:
Derive from the module’s
ImplBaseclass and implement the required virtual methods.Compile your implementation as a separate shared library.
In your application, instantiate your implementation and pass it to the interface constructor:
// Example: custom PostProcess implementation
auto my_postprocess_impl = std::make_shared<MyCustomPostProcess>(/* ... */);
vart::PostProcess postprocess(my_postprocess_impl);
// Example: custom PreProcess implementation
auto my_preprocess_impl = std::make_shared<MyCustomPreProcess>(/* ... */);
vart::PreProcess preprocess(my_preprocess_impl);
The interface class delegates all calls to your implementation. The rest of the pipeline (frame flow, inference, overlay) remains unchanged.
Custom PostProcessing and the InferResult Chain#
The built-in PostProcess implementations produce vart::InferResult objects using the existing result types: ClassificationResData, DetectionResData, and SegmentationResData. If your custom post-processing produces results compatible with one of these types, you can use the existing InferResult, MetaConvert, and Overlay modules as-is.
If your post-processing produces a different result format, you also need to provide:
A custom
InferResultimplementation to hold your result data.A custom
MetaConvertimplementation that understands your newInferResultand translates it intoOverlayShapeInfofor theOverlaymodule.
This chain (PostProcess → InferResult → MetaConvert → Overlay) ensures that custom inference results can be visualized end-to-end.
Compiling Custom Implementations as Separate Libraries#
Custom implementations can be compiled as shared libraries so you don’t need to recompile vart-x. The pattern is the same for any module:
# Example: compile a custom PostProcess implementation as a shared library
CXX = $(CROSS_COMPILE)g++
CXXFLAGS = $(shell pkg-config --cflags vart-x)
LDFLAGS = $(shell pkg-config --libs vart-x)
libvart_postprocess_custom.so: my_postprocess.cpp
$(CXX) -shared -fPIC $(CXXFLAGS) -o $@ $< $(LDFLAGS)
The same pattern applies to custom InferResult and custom MetaConvert libraries. Link the resulting shared library with your application.