Vitis AI Runtime (VART) Overview#
The Vitis AI Runtime (VART) is the software layer used to execute compiled machine learning (ML) models and surrounding pipeline stages on Versal™ AI Edge Series Gen 2 platforms. This chapter introduces how the pieces fit together and suggests an order for reading the rest of the documentation. For Vitis AI 6.2 feature highlights and Vitis AI 6.1 → Vitis AI 6.2 migration notes, see What’s new in Vitis AI 6.2 at the end of this page.
VART primarily consists of VART-ML (model execution APIs) and VART-X (video and I/O pipeline building blocks). Some reference applications in this guide also use ONNX Runtime + Vitis AI Execution Provider as an alternative inference path.
How VART-ML and VART-X connect#
VART-ML focuses on running the compiled model: loading the compiler partition (vaiml_par_0—graph, metadata, and binaries from the Vitis AI compiler mapped to the AI Engine/NPU—typically a model cache directory or a .rai image), describing inputs and outputs as NpuTensor objects, and executing synchronous or asynchronous Runner APIs.
VART-X focuses on everything around the model in a typical vision application: frame buffers; preprocess (resize, format conversion, normalization) through the VART-X PreProcess module and its image-processing pipeline; postprocess (softmax, NMS, custom); metaconvert and overlay for visualization; and helper types such as InferResult and Memory. Preprocess can run on programmable logic (PL)—the Versal FPGA fabric—or on the CPU, depending on platform and configuration. The compiled ML model executes on the AI Engine/NPU, while PL can provide accelerated image-processing and other platform-defined kernels when integrated in the design.
ONNX Runtime with the Vitis AI Execution Provider is an alternative inference backend that can be used in similar application patterns.
Three deployment lanes#
Use this to decide where to start.
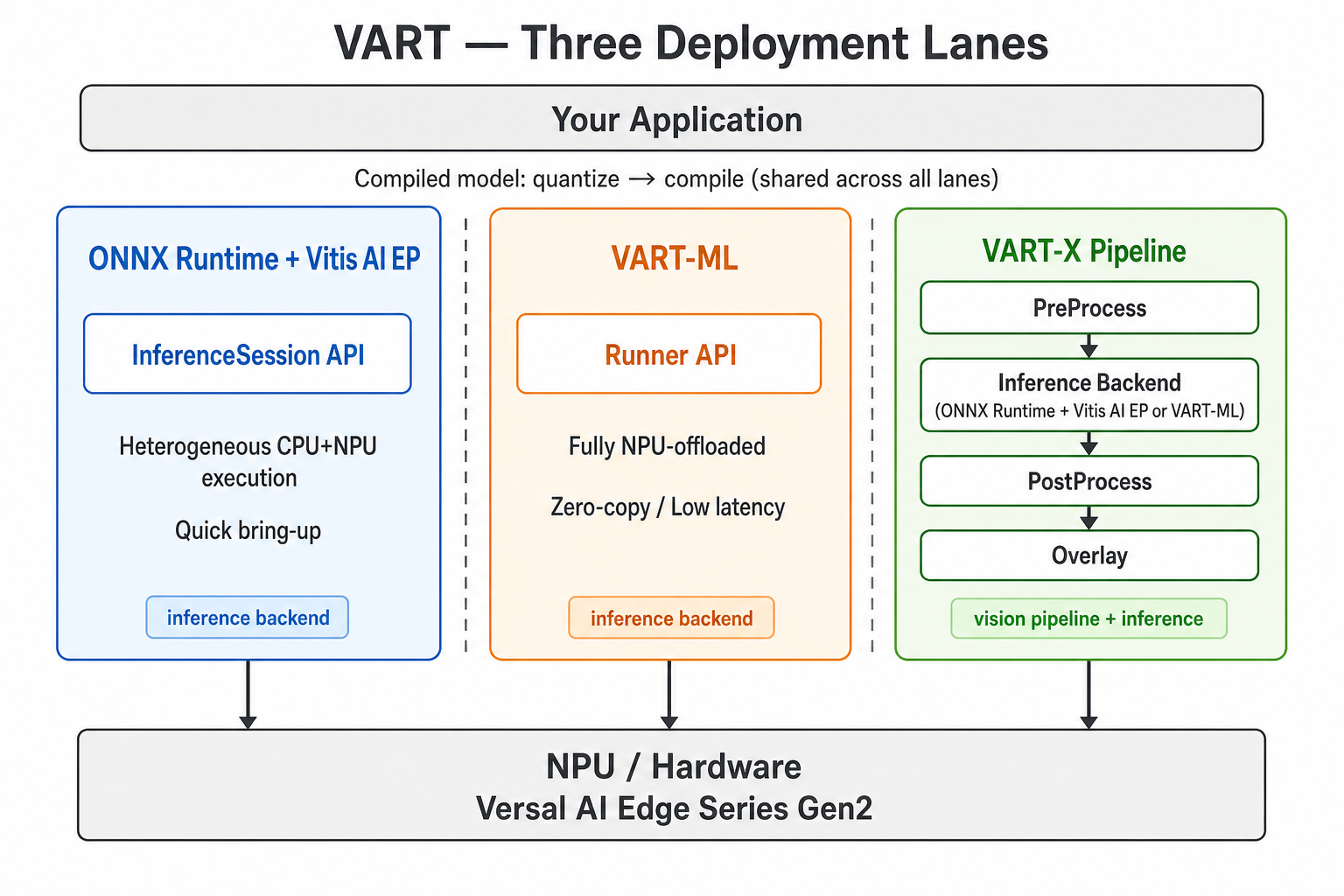
ONNX Runtime + Vitis AI Execution Provider — Familiar ONNX Runtime
InferenceSessionAPIs. Often used for quick bring-up.VART-ML — C++ Runner API for compiled models that execute on the NPU, including fully offloaded models and models compiled with the CPU partition feature for heterogeneous NPU/CPU execution where supported. Provides explicit tensors and optional zero-copy when you manage hardware buffers. Use when latency and throughput dominate.
VART-X–centric pipelines — Device,
VideoFrame, preprocess, postprocess, overlay, and related modules for end-to-end vision flows. You still run inference inside the pipeline using either ONNX Runtime + Vitis AI EP or VART-ML; VART-X owns the frame lifecycle and non-model stages.
On the host, the same Vitis AI quantization and compilation flow produces the compiled model artifact for all three lanes above. The lanes differ on the target in how you invoke inference and move data: ONNX Runtime session APIs versus VART-ML Runner APIs versus VART-X pipeline orchestration, and how tensors and buffers are allocated and shared—not in requiring a separate compiler workflow per lane.
For INT8 models on VART, compile-time flags and runtime quantization configuration (VART-X JSON, VART-ML APIs, or manual scales) are described in Quantization Parameters for VART Applications.
Suggested reading order#
Follow this order to build the story from scope to code:
Choosing ONNX Runtime + Vitis AI EP vs VART-ML (and the role of VART-X) — Introduction: VART X and VART ML
VART-ML architecture (Runner, tensors, zero-copy) — VART ML Architecture Overview
VART-X architecture (modules and data flow) — VART X Architecture Overview
Application development walkthrough — VART Application Development
Prebuilt examples matrix and quick starts — Reference Applications
After that, use debugging, tensor layout reference, the NPU Format Selection Guide (preprocess-config.colour-format for vision pipelines), Post Processing Functions, Quantization Parameters for VART Applications, and the VART ML API class list and VART X API class list in this chapter as needed.
What’s new in Vitis AI 6.2#
The following summarizes notable VART-ML and VART-X additions in Vitis AI 6.2, followed by migration and compatibility notes when moving from Vitis AI 6.1.
Feature summary#
VART-ML#
New features
API for creating sub-tensor views over parent tensors, enabling multiple tensor views as offsets within a single allocation (
Runner::allocate_sub_tensor).API for exporting the underlying buffer as a dma-buf file descriptor, enabling zero-copy interop with other subsystems (
NpuTensor::export_buffer).
Enhancements
allocate_npu_tensor— Now supportsvart::TensorType::CPUin addition tovart::TensorType::HW.Asynchronous execution — Configurable thread-pool depth and optional in-order delivery mode for
ExecuteAsyncCallback.
VART-X#
New features
API for exporting and importing dma-buf file descriptors, enabling zero-copy interop with other subsystems (
vart::Memory,vart::VideoFrame).Post-processing functions for segmentation models: Softmax, Argmax, and Sigmoid (
SOFTMAXSEG,ARGMAXSEG,SIGMOID).Color formats added for FP16, BF16, and planar variants of RGB/BGR (
vart::VideoFormat).
Enhancements
InferResult/MetaConvert/Overlay— Enhanced to support segmentation results visualization.Post-processing functions — Added FP16 tensor support.
Bug fixes
YOLO post-processing — Fixed double sigmoid being applied to the objectness score.
Migration and compatibility (Vitis AI 6.1 to Vitis AI 6.2)#
VART-ML#
Runner::allocate_npu_tensor— ReturnsNpuTensordirectly and throws on failure; removeStatusCodechecks and use exception handling.Runner::ExecuteAsyncCallback— Removedvoid* user_data; capture context via the callable itself.Runner::wait— Usestd::chrono::millisecondsinstead of raw integers for timeouts.NpuTensorcopies — Now share underlying buffer state; update code that assumed unique ownership.NpuTensor::get_buffer/get_virtual_address— Const-ness enforced via separate overloads.Public headers —
<iostream>removed; add explicit includes if needed.
VART-X#
InferResScaleInfo— Replacedwidth_scale_factor/height_scale_factorwith explicit dimension fields; usemodel_input_width,model_input_height,input_frame_width, andinput_frame_heightinstead.
See also
For the high-level product view of quantization, compilation, and deployment, see Vitis AI Overview at the start of this guide.